Inverted Index
This is by far the most used search data structure, and it's great for capturing lexographic similarities such as unique words in a document, common words in documents, and things like that
Allows us to compare a users string query to a large corpus of documents
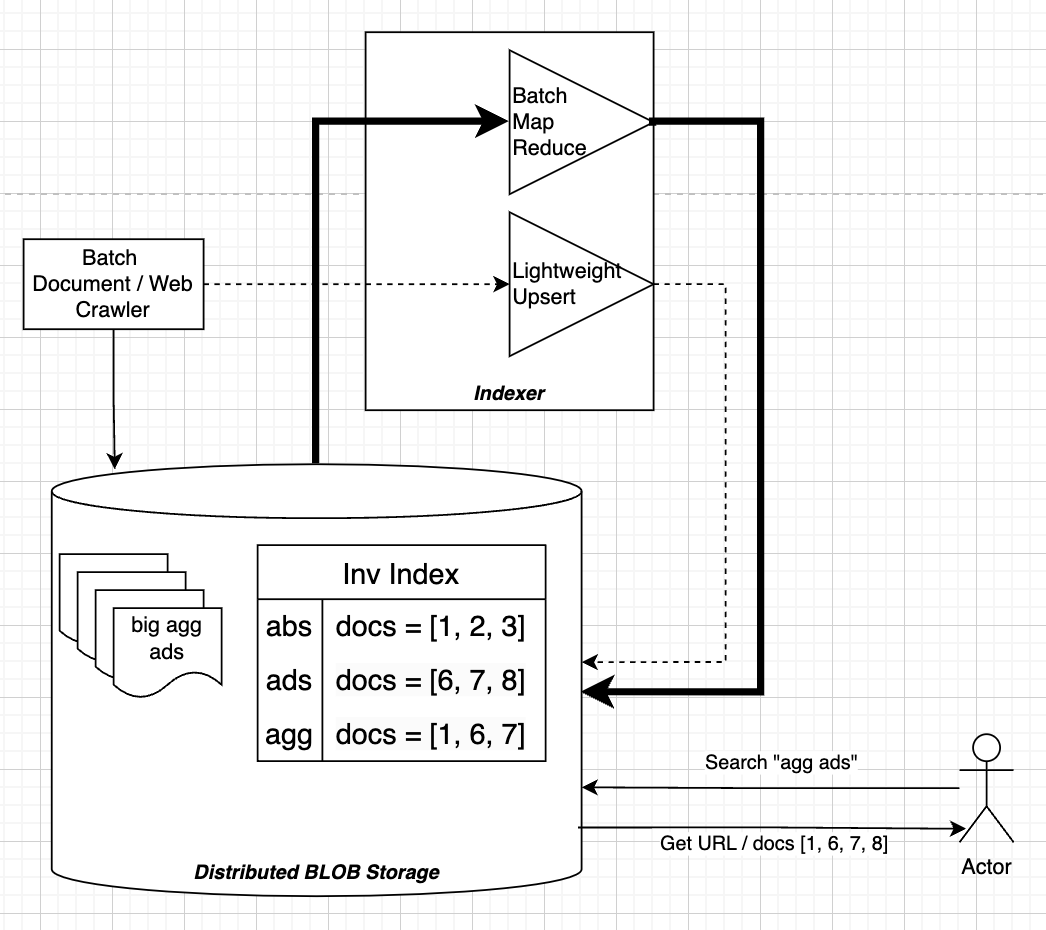
Discussion
This architecture does allow for batch and online (fast) processing of documents, but there are pieces missing
- Slow: The serving is done from a lookup on Blob Storage which sits on disk
- Frail: Certain words in documents or in query might be misspelled
- Misses Context: "River Bank" and "Bank Deposit" would both return the same documents referring to "Bank"
The inverted index is going to be a truly core data structure for search moving forward, but there are ways to improve the actual serving and comparisons which has led to many other discoveries